Neural Ordinary Differential Equations
NeurIPS award papers
Last month, Montréal hosted the 2018 Neural Information Processing Systems (NeurIPS) . Each year, the conference makes a handful of “Best Paper” awards. The 2018 winners were:
- Non-Delusional Q-Learning and Value-Iteration
- Optimal Algorithms for Non-Smooth Distributed Optimization in Networks
- Nearly Tight Sample Complexity Bounds for Learning Mixtures of Gaussians via Sample Compression Schemes
- Neural Ordinary Differential Equations
The Test of Time award winner was the worthy The Tradeoffs of Large Scale Learning, which showed the value of using simple computations over lots of data instead of complex computations over less data for a fixed compute budget. Here we’ll dig into just one of the Best Paper award winners, but one we find very exciting.
Neural Ordinary Differential Equations
Neural networks compose layer-wise transformations on hidden states. Feed forward networks compose these transformations sequentially: each layer takes the previous layer as input, and outputs a new hidden state. In residual networks (ResNets) - introduced in Deep Residual Learning for Image Recognition - the transformations have a more specific form: each layer is the sum of the previous layer and a transformation on it. The intuition is that it is easier to learn a function for the difference between layers - a small correction - than model a new, improved output directly.
One of the problems that ResNets helped to solve was training very deep neural networks. In general, a deeper network is able to approximate more complex functions than an otherwise equivalent, shallower one. However, deep networks are notoriously difficult to train - training error can actually increase as more layers are added. By modelling the difference between layers, ResNets made it substantially easier to train very deep networks. If we take the idea of adding layers to its logical extreme and include infinitely many layers, each modelling an infinitesimally small change, it’s possible to express this transformation mathematically as an ordinary differential equation (ODE): an equation that describes a rate of change of one state as a function of a parameter. The innovation in Neural Ordinary Differential Equations is to take exactly that step, and replace the discrete hidden layers with a single function specified by an ODE; effectively giving the network continuous depth. ODEs are in general difficult to solve, but mature software exists to approximate them numerically, and the paper provides details of how the gradients necessary to train a continuous depth neural network are calculated through an ODE solver.
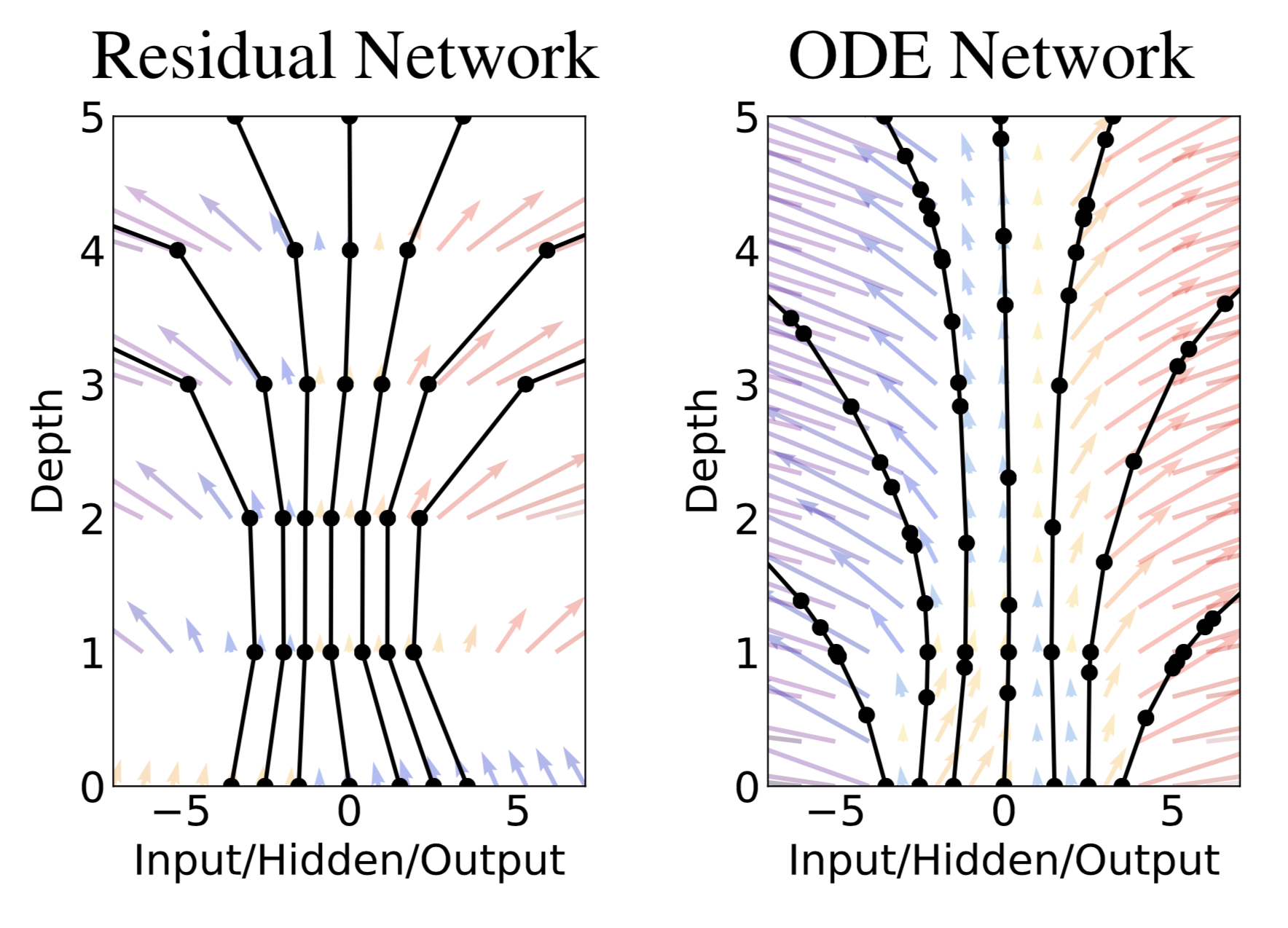
The discrete steps of a Residual network with fixed evaluation points compared to a continuous depth ODE network which can be evaluated at any point in the transformation (circles are evaluation points in each). Image credit.
Since there are no layers to constrain it, the network must be evaluated at continuous timepoints. This facilitates adaptive computation, allowing one to trade off evaluation time with accuracy, by evaluating the continuous transformation at more or fewer points. It is possible to make this choice dynamically - for instance, one might train an ODE network using many evaluations for high accuracy, but evaluate it at only a few points when computation time must be minimized.
The paper shows that ODE networks have comparable performance to a ResNet on MNIST with only slightly more than a third of the parameters to train and constant memory requirements (whereas ResNet models’ memory requirements grow linearly with number of layers). The authors also demonstrate application to normalising flows - transformations of probability densities - showing that this continuous depth method can result in better approximations with fewer training iterations.
Perhaps the most exciting effect of replacing discrete layers with a continuous transformation is the ability to model continuous or irregularly sampled time series without discretising into fixed time steps; the authors suggest medical records and network traffic specifically. The paper shows the application to the toy problem of reconstructing a spiral from noisy measurements, achieving better results than a discrete recurrent neural network.
Neural ODEs are certainly in their infancy, but offer several novel tradeoffs, and we’ll be watching closely for new capabilities they facilitate. We’re especially eager to see continuous depth models used on continuous time series with real world data.
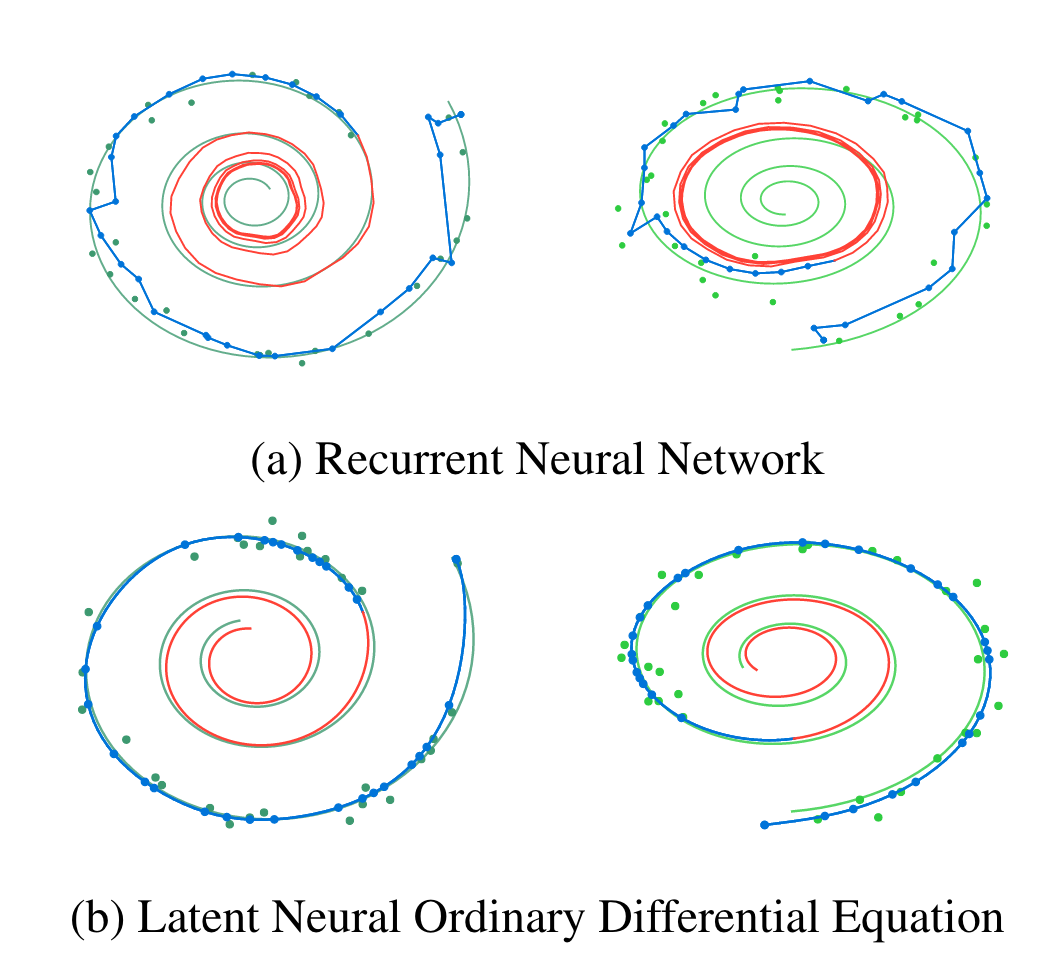
ODE networks result in a much smoother approximation of two dimensional spirals than recurrent networks with discrete timesteps. Image credit.